 Last week Catherine Cronin brought Alice Marwick’s review of Nathaniel Tkacz’s Wikipedia and the Politics of Openness, to my attention and it’s left me with a lot of food for thought. I haven’t had a chance to read Tkacz’s book yet but there are a couple points that I’d like to pick up on from the review, and one in particular that relates to the post I wrote recently on Jisc’s announcement that it intended to “retire” Jorum and replace it with a new “App and Content store” : Retire and Refresh: Jisc, Jorum and Open Education.
Last week Catherine Cronin brought Alice Marwick’s review of Nathaniel Tkacz’s Wikipedia and the Politics of Openness, to my attention and it’s left me with a lot of food for thought. I haven’t had a chance to read Tkacz’s book yet but there are a couple points that I’d like to pick up on from the review, and one in particular that relates to the post I wrote recently on Jisc’s announcement that it intended to “retire” Jorum and replace it with a new “App and Content store” : Retire and Refresh: Jisc, Jorum and Open Education.
I tend to shy away from socio-political discussions about the nature of openness as I find that they often become very circular, and very contentious, very quickly. I do agree with Tkacz and Marwick that openness is inherently political but I certainly don’t believe that openness is intrinsically neoliberal. To my mind this analysis betrays a rather US centric view of the open world and fails to take into consideration many other global expressions of openness.
If I’m interpreting Marwick correctly, Tkacz also seems to be arguing that openness must necessarily be non-hierarchical, which is an interesting perspective but not one that I wholly buy into. While I think we need to be aware of the dangers of replicating existing hierarchical power structures in open environments, I think it’s somewhat idealistic to expect open initiatives to flourish without any power structures at all. So yes, there are hierarchical power structures inherent in Wikipedia, but I think there are many more egregious examples of openwashing out there.
The point that really struck me in Marwick’s review was the reference to Jonathan Zittrain’s 2008 book The Future of the Internet – And How to Stop It in which the author charts the evolution from generative to tethered devices.
 “The PC revolution was launched with PCs that invited innovation by others. So too with the Internet. Both were generative: they were designed to accept any contribution that followed a basic set of rules (either coded for a particular operating system, or respecting the protocols of the Internet). Both overwhelmed their respective proprietary, non-generative competitors, such as the makers of stand-alone word processors and proprietary online services like CompuServe and AOL. But the future unfolding right now is very different from this past. The future is not one of generative PCs attached to a generative network. It is instead one of sterile appliances tethered to a network of control.”
“The PC revolution was launched with PCs that invited innovation by others. So too with the Internet. Both were generative: they were designed to accept any contribution that followed a basic set of rules (either coded for a particular operating system, or respecting the protocols of the Internet). Both overwhelmed their respective proprietary, non-generative competitors, such as the makers of stand-alone word processors and proprietary online services like CompuServe and AOL. But the future unfolding right now is very different from this past. The future is not one of generative PCs attached to a generative network. It is instead one of sterile appliances tethered to a network of control.”
The Future of the Internet – And How to Stop It
Jonathan Zittrain
Marwick elaborates on the this generative – tethered dichotomy and situates it in our current technology context.
“Those in the former (generative) group allow under-the-hood tinkering, or simply messing with code, are championed by the maker movement, and run on free and open-source software. Tethered devices, on the other hand, are governed by app stores and regulated by mobile carriers: this is the iPhone model….The most successful apps of today, from Uber to Airbnb to Snapchat, are participatory and open only in the sense that anyone is free to use them and generate revenue for their owners.
Most of these apps use proprietary formats, don’t play well with others, make it difficult for users to port their content from one to another, and are resolutely closed-source.”
Open Markets, Open Projects: Wikipedia and the politics of openness
Alice E. Marwick
Now, I’m not sufficiently familiar with Zittrain’s work to know if his thinking is still considered to be current and relevant, but his warnings about a future of closed technologies tethered to a network of control, rather amplified the alarm bells that have been ringing in my head since Jisc announced the creation of their App and Content store. As I mentioned in my previous post, the idea of an App Store sits very uneasily with my conception of open education. Also I can’t help wondering what role, if any, open standards will play in the development of the new app store to prevent lock-in to proprietary applications and formats.
Zittrain suggested that developing community ethos is one way to “stop the future” and counter technology lockdown.
“A lockdown on PCs and a corresponding rise of tethered appliances will eliminate what today we take for granted: a world where mainstream technology can be influenced, even revolutionized, out of left field. Stopping this future depends on some wisely developed and implemented locks, along with new technologies and a community ethos that secures the keys to those locks among groups with shared norms and a sense of public purpose, rather than in the hands of a single gatekeeping entity, whether public or private.”
The Future of the Internet – And How to Stop It
Jonathan Zittrain
I absolutely agree that when it comes to the development of education content and technologies we need a community ethos with shared norms and a sense of public purpose, but to my mind it’s increased openness, rather than more locks and keys that will provide this safeguard. In the past Jisc played an important public role by fostering communities of practice, supporting the development of innovative open technologies and sharing common practice and I sincerely hope that, rather than becoming a single gatekeeper to the community’s education content and applications, it will continue to maintain this invaluable sense of public purpose.

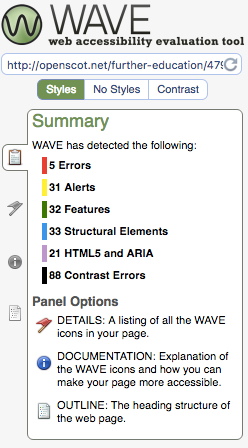 The blog I chose was the Open Scotland, a simple WordPress blog running on Reclaim Hosting and you can see the results here. To be honest most of the errors and alerts didn’t surprise me as they relate to heading abuse and images without alt text. One thing that did surprise me though is that justified text is problematic.
The blog I chose was the Open Scotland, a simple WordPress blog running on Reclaim Hosting and you can see the results here. To be honest most of the errors and alerts didn’t surprise me as they relate to heading abuse and images without alt text. One thing that did surprise me though is that justified text is problematic.



